One of the most interesting shifts in technology began twenty years ago with Google’s release of MapReduce, a programming model and reference implementation for distributed processing of big datasets on clustered computers.
Throughout the 20th century, most cutting edge technologies coming out of the US were either invented or made viable in government research labs. The airplane was of course invented by the Wright brothers, but shortly thereafter the US government purchased a plane from them and designed repeatable manufacturing processes, making the technology much more accessible. A similar pattern exists with the transistor, radar, the internet, and other pivotal innovations of the last hundred years.
These technologies were operationalized by or with help from the government and have since been applied in private industries and made broadly available to end users. Starting about twenty years ago, leading internet companies flipped that script in one respect by developing technologies in-house that are now being used across government agencies. These technologies kicked off the notorious “big data” movement.
In 2004, Jeff Dean and Sanjay Ghemawat of Google released a paper titled MapReduce: Simplified Data Processing on Large Clusters, which described a programming model for distributed processing of large datasets on commodity hardware. The datasets which powered Google Search were growing so quickly that conventional methods of processing could not keep up, and Google needed a new method. Over the last eighteen years since that release, the innovation behind MapReduce has led to a Cambrian explosion of data processing tools and has brought the (now over-used) term “big data” into modern corporate vernacular.
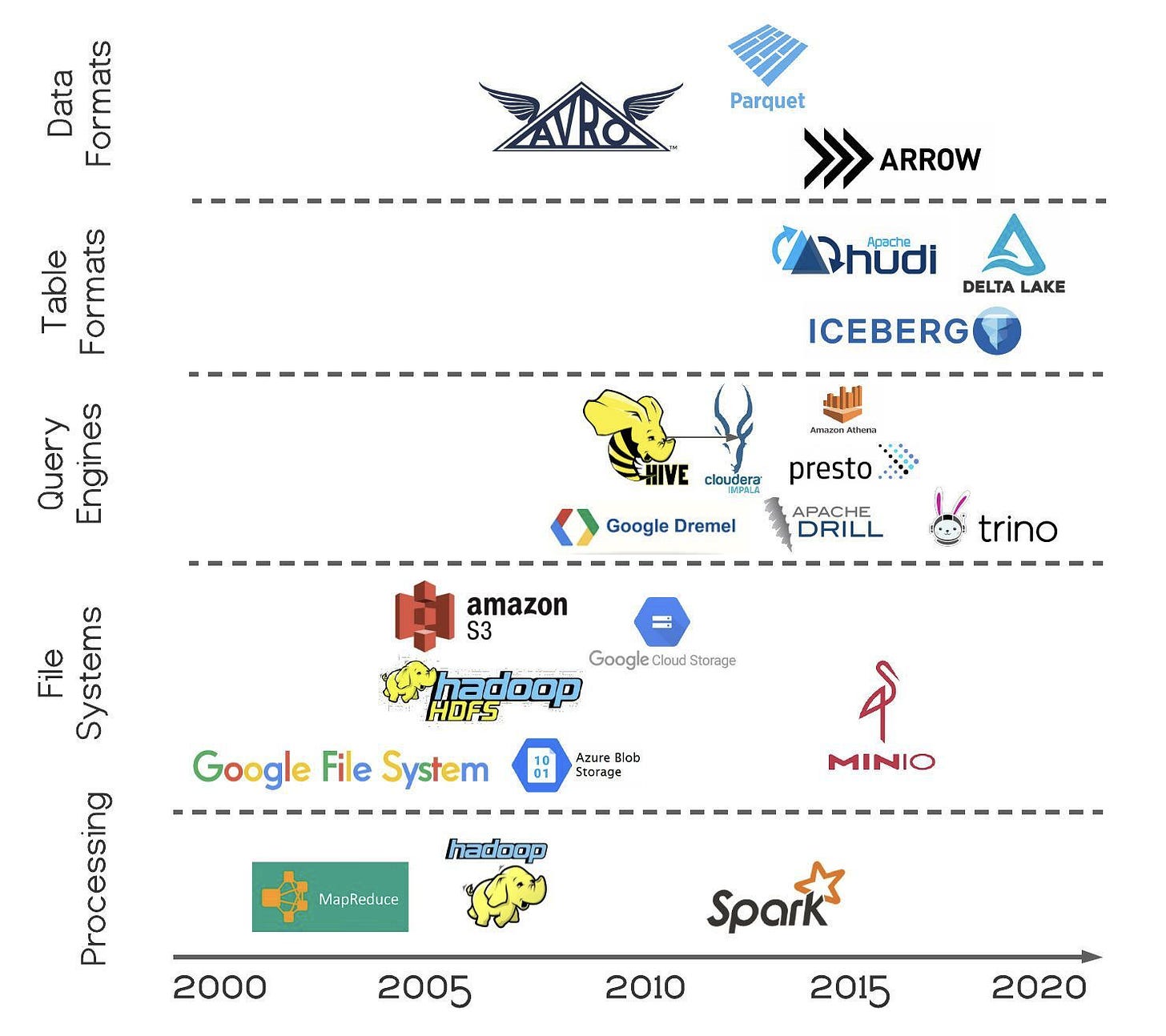
I decided to map out a few of the key technologies from this movement and place them on a timeline to give more context into where each innovation fits in the landscape.
To briefly recap, MapReduce (and the original Google File System) catalyzed the movement in 2004. Two years later, Hadoop and HDFS (Hadoop Distributed File System) were released by teams at Yahoo as an implementation of the MapReduce programming paradigm. Around this same time, Amazon debuted their public cloud with the release of S3 (Simple Storage Service), pioneering cloud object storage with nearly unlimited scalability and eventual consistency. By 2010, these distributed file systems had become so popular as an easy way to store data across many homogeneous nodes that a new class of query engines emerged (Dremel, Hive, Impala, Drill, etc.) to help analytical users query these distributed datasets and quickly derive value
As the data lake ecosystem became an enterprise standard, practitioners wanted to interact with them how they had always interacted with databases by leveraging transactions, change streams, and record-level updates. Out of this need emerged projects now just gaining steam like Hudi, Iceberg, and Delta Lake. Data formats have begun to evolve from the traditional row-based orientation to columnar formats like Parquet and Arrow since large-scale analytical workloads work better with columnar.
I’d like to keep my analysis simple with three insights that I gather from viewing these technologies on a twenty year timeline.
The Data Lakehouse architecture is the result of two decades of modular components being developed at increasing levels of abstraction. Hadoop and early file systems proved that petabytes of data can be stored and transformed on lots of cheap hardware. With this new ability, thousands of companies started storing data in Hadoop clusters to the point that analysts expected to write SQL to query the data in the way they were used to doing in data warehouses, leading to the query engine layer. And finally, at the highest levels of abstraction, table and data formats have been defined to standardize storage and compute and to make the “Lakehouse” a transactional system. Looking ahead, I’d expect this trend to continue and for more companies building around this architecture to emerge.
The rate of innovation in a category is driven more by low switching costs than by room for improvement. That is to say — the fact that Hadoop is still broadly used sixteen years after its release is not to say that Hadoop doesn’t have its challenges, but it does show how heavy the lift is to migrate off systems that are both stateful and at scale. Similarly, Spark has a few drawbacks including no native support for real-time processing, an expensive cost structure, and problems with handling small file sizes. However, because one’s choice of batch processing framework is a multi-year decision, this layer of the stack has a much longer lifecycle than query engines, for example, which are more plug and play.
Columnar data formats continue to spread closer to the end data consumer. Columnar formats (where data is stored contiguously column by column) are generally more efficient for analytical use cases, whereas row-based formats (each row of data is stored contiguously) better serve transactional use cases and certain types of search queries. The amount of data out of which organizations try to mine value has exploded (not coincidentally) along with the timeline shown in the chart above. This increased volume makes data compression all the more important, which columnar formats enable more easily than row-based formats. The result is that these columnar formats have moved from the file level (Parquet), to in-memory (Arrow), and even more recently to network protocols and client SDKs (Arrow Flight).
Kamal Shah and Vibhav Sreekanti are serial entrepreneurs whose Prophet AI platform uses automation to cut mean time to response to cybersecurity threats by 10x.
The Cyber Leaders are innovative CISOs and other top cybersecurity leaders, comprising a community that will benefit each member and the Bain Capital network.